![]()
The Five Minute Introduction to SeqLike
This notebook aims to teach you, in under 5 minutes worth of reading, all about SeqLike and its major features.
Imports
import matplotlib.pyplot as plt
import numpy as np
from Bio.Seq import Seq
from Bio.SeqRecord import SeqRecord
import pandas as pd
from seqlike import SeqLike, ntSeqLike, aaSeqLike
from seqlike.alphabets import STANDARD_NT, STANDARD_AA
What is SeqLike all about?
SeqLike aims to be an omnibus Python object that bridges between different sequence representations: strings, SeqRecord objects, NumPy arrays, and more. It draws heavily upon BioPython's SeqRecord objects, and in most cases can be a drop-in replacement with additional powerful features that bioinformaticians familiar with BioPython will absolutely love ❤️.
What problems does SeqLike solve?
At its core, SeqLike solves the following problems:
- Sequence representation inter-conversion (AA vs. NT, and str/Seq/SeqRecord/arrays) via a single object's API.
- Convenience APIs to manipulate and/or visualize of a collection of sequences.
Sequence Representation
Constructing SeqLike objects
SeqLikes can be constructed from nucleotide or protein sequences with an explicit sequence type set. They can wrap string, Seq, SeqRecord, and list/arrays: anything that is like a sequence. This will be clear as we proceed, but for now, we'll just demonstrate with strings:
aa_sequence = "PKSAAEKAGLKAGDPKSAAEKAGLKAGDPKSAAEKAGLKAGDPKSAAEKAGLKAGD"
s_aa = SeqLike(aa_sequence, seq_type="aa") # case insensitive
nt_sequence = "AUCTCUCUAUTACUA"
s_nt = SeqLike(nt_sequence, seq_type="nt") # case insensitive, can be "nt", "dna", or "rna"
If you know the sequence type ahead of time, we recommend using the helper functions ntSeqLike and aaSeqLike for convenience. These are not subtypes, but functions that return SeqLike objects of the apropriate seq_type, coercing if necessary.
s_aa = aaSeqLike(aa_sequence)
s_nt = ntSeqLike(nt_sequence)
s_aa_coerced = aaSeqLike(nt_sequence) # every NT sequence is a valid AA SeqLike with the default alphabets...
try:
s_nt_coerced = ntSeqLike(aa_sequence) # In contrast, virtually every AA sequence is NOT a valid NT SeqLike!
except TypeError as e:
print(e)
The SeqLike __repr__ (string representing) gives us lots of useful information about the sequence.
This one has no nucleotide representation, it has an amino acid representation, and the amino acid representation has an auto-generated ID,
unknown name, and unknown description.
s_aa
Working with SeqLikes with dual NT and AA representations
For many workflows, it is powerful to maintain a dual representation of a sequence with AA and NT forms. SeqLike supports this, and has a notion of the "current" sequence type. All methods (e.g. sub-indexing) act on the current sequence type, but are reflected in the non-active type.
Given a DNA or RNA sequence, as long as the nucleotide sequence is a multiple of 3, you can always convert it to the amino acid representation.
s_aa = s_nt.aa()
print(s_aa.__repr__()) # current form marked by ***
# Note: s_nt is unchanged, we alwas return copies
print(f"\n{id(s_nt)=}, {id(s_aa)=}")
If the length is not a multiple of 3, then translation is disallowed:
try:
s_nt[:-1].aa()
except TypeError as e:
print(e)
In contrast to translation, back-translation is ambigious and ill-defined because there are multiple valid codons for each amino acid. For instance, the amino acid leucine can be encoded in RNA as CUU, CUC, CUA, and CUG.
Therefore, to use .nt(), you must use a callable that takes an AA sequence and returns a sequence in NT form. We've included several codon tables (implemented as dictionaries) and associated codon maps (implemented as callables) in codon_tables.py. If you don't provide a codon_map, we raise an error.
from seqlike.codon_tables import human_codon_map
try:
s_aa = aaSeqLike(aa_sequence)
s_aa.nt()
except AttributeError as e:
print(e)
print("\n")
s_aa = aaSeqLike(aa_sequence, codon_map=human_codon_map)
s_aa.nt()
A final note: .aa() and .nt() call .translate() and .back_translate() internally if needed. If the SeqLike has both an AA and an NT, then .aa() and .nt() just swap the active form of the sequence and return a copy.
Manipulating SeqLikes with NT and AA representations (slicing, padding, etc.)
In general, all typical sequence methods work on the current active form of the sequence. For example, if you have an AA SeqLike and you slice it, it will return an AA SeqLike where the NT form as been sliced as well.
s_nt = SeqLike(nt_sequence, seq_type='nt')
s_aa = s_nt.aa()
s_aa[:3].nt()
When you slice an NT SeqLike that has an AA representation, as long as you slice in-frame, you will slice the AA representation as well.
s_nt.aa().nt()[0:6]
Slicing out of frame will give you weird behaviour; BioPython will give you a warning, though it's up to you to know what you're doing.
s_nt.aa().nt()[0:4]
Finally, here is example usage of a couple of miscellaneous methods:
# operates on the nt
print(f"{len(s_nt)=}")
# operates on the aa
print(f"{len(s_nt.aa())=}")
# pads the nt, adding a gap character "-"
print(s_nt.pad_to(18))
# pads the aa, using the same gap character "-"
print(s_nt.aa().pad_to(18))
Initialization from and conversion between different datatypes
For machine learning purposes, sequences need to be encoded numerically. This is typically done by encoding each letter in the sequence in two ways:
- as a one-hot categorical distribution over alphabet symbols (one hot encoding)
- as an integer-valued index over alphabet symbols (index encoding)
SeqLike has robust support for both. Crucially, numercial representations require an ordered alphabet to map between letter and number. We provide a default, but See alphabets.py for more.
# Manually create many data structures representing the same sequence
s_str = 'ACGTTT'
s_seq = Seq(s_str)
s_seqrecord = SeqRecord(s_seq)
s_onehot = [[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0]]
s_index = [1, 2, 3, 4, 4, 4]
for rep in [s_str, s_seq, s_seqrecord, s_onehot, s_index]:
# Default alphabet for NT is "-ACGTUN". See alphabets.py for more.
s_rep = ntSeqLike(rep, alphabet=STANDARD_NT)
assert len(s_rep)==6
assert s_rep._type == "NT"
assert len(s_rep.aa()) == 2
assert s_rep.aa()._type == "AA"
print(s_rep)
Conversion to strings, Seqs and Seqrecords
for rep in [s_str, s_seq, s_seqrecord, s_onehot, s_index]:
s_rep = ntSeqLike(rep, alphabet=STANDARD_NT)
print(f"{s_rep.to_str()=}")
print(f"{s_rep.to_seq()=}")
print(f"{s_rep.to_seqrecord()=}")
print("------------------")
Conversion to arrays
It is easy to generate the one-hot encoding or index encodings of any SeqLike:
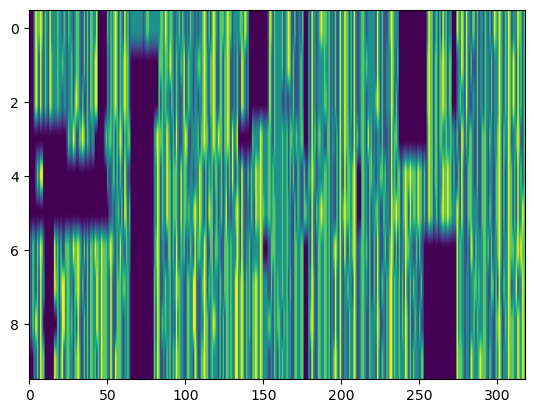
plt.imshow(s_nt.to_onehot())
plt.imshow(np.atleast_2d(s_nt.to_index()))

Quacking like SeqRecords
SeqLike objects, as we mentioned above, are highly inspired by SeqRecord objects. This means that, if you're used to dealing with collections of SeqRecord objects, you can actually access the underlying attributes easily via the same attribute accessors. Here are a few examples.
Commonly-used SeqRecord attributes
s_nt
s_nt.id
s_nt.description
s_nt.name
s_nt.dbxrefs
Letter annotations
Letter annotations are also accessible!
s_nt.letter_annotations
They can also be set!
As long as the value fulfills the SeqRecord letter annotation requirement
of being a list of the same length as the main SeqRecord,
you can add to the letter_annotations attribute.
For example, if we want to add DNA methylation state:
len([
None,
None,
"methylated",
None,
None,
None,
"methylated",
])# + [None] * 14)
s_nt.letter_annotations["methylation_state"] = [
None,
None,
"methylated",
None,
None,
None,
"methylated",
] + [None] * 8
s_nt.letter_annotations
SeqLike objects quack like SeqRecord objects. We think that means you can take SeqRecord objects and replace them with SeqLike objects with no issue. (But if you find an edge case we haven't yet covered, be sure to let us know!)
Working with collections of SeqLikes in Pandas
SeqLike also aims to simplify common tasks when working with collections of sequences. We provide extensive integration with pandas Series via accessor methods, making life supremely easy.
Accessor methods are exposed by the automatically generated .seq attribute in all pandas Series objects. If a Series is all SeqLikes, then this namespace will contain many helpful methods for working with them. Many operations return a new Series of SeqLikes, which added to a DataFrame as a new column and then futher manipulated by using .seq, again.
Let's say we have the following sequences:
seqs = [
'LVSIPASSHGKRGLSVSIDPPHGPPGCGTEHSHTVRVQGVDPGCMSPDVKNSIHVGDRILEINGTPIRNVPLDEIDLLIQETSRLLQLTLE',
'LISMPAATDGKRGFSVSVEGGCSSYATGVQVKEVNRMHISPDVRNAIHPADRILEINGAPIRTLQVEEVEDLIRKTSQTLQLLIE',
'LISMPATTECRRGFSVSVESASSNYATTVQVKEVNRMHISPNNRNAIHPGDRILEINGTPVRTLRVEEVEDAINQTSQTLQLLIE',
'SLKVSTSGELSGVGLQINVNPEVDVLEVILPLPGSPAEAAGIEAKDQILAIDGIDTRNIGLEEAAARMRGKKGSTVSLTVK',
'SFNESINLSLEGIGTTLQSEDDEISIKSLVPGAPAERSKKLHPGDKIIGVGQATGDIEDVVGWRLEDLVEKIKGKKGTKVRLEIE',
'NTEMSLSLEGIGAVLQMDDDYTVINSMVAGGPAAKSKAISVGDKIVGVGQTGKPMVDVIGWRLDDVVALIKGPKGSKVRLEIL',
'QQLIEKGLVQRGWLGVQIQPVTKEISDSIGLKEAKGALITDPLKGPAAKAGIKAGDVIISVNGEKINDVRDLAKRIANMSPGETVTLGVW',
'QQILEFGQVRRGLLGIKGGELNADLAKAFNVSAQQGAFVSEVLPKSAAEKAGLKAGDIITAMNGQKISSFAEIRAKIATTGAGKEISLTYL',
'QLIDFGEIKRGLLGIKGTEMSADIAKAFNLDVQRGAFVSEVLPGSGSAKAGVKAGDIITSLNGKPLNSFAELRSRIATTEPGTKVKLGLL',
'QMVEYGQVKRGELGIMGTELNSELAKAMKVDAQRGAFVSQVLPNSSAAKAGIKAGDVITSLNGKPISSFAALRAQVGTMPVGSKLTLGLL',
]
names = [
'LIMK1_HUMAN/165-255',
'LIMK2_CHICK/152-236',
'LIMK2_RAT/152-236',
'CTPA_SYNP2/102-182',
'PRC_HAEIN/244-328',
'PRC_ECOLI/238-320',
'DEGPL_BARHE/289-378',
'HTOA_HAEIN/268-358',
'DEGQ_ECOLI/257-346',
'DEGP_ECOLI/279-368',
]
df = pd.DataFrame({'names':names, 'aa_seqs':[aaSeqLike(x) for x in seqs]})
df
| names | aa_seqs | |
|---|---|---|
| 0 | LIMK1_HUMAN/165-255 | LVSIPASSHGKRGLSVSIDPPHGPPGCGTEHSHTVRVQGVDPGCMSP... |
| 1 | LIMK2_CHICK/152-236 | LISMPAATDGKRGFSVSVEGGCSSYATGVQVKEVNRMHISPDVRNAI... |
| 2 | LIMK2_RAT/152-236 | LISMPATTECRRGFSVSVESASSNYATTVQVKEVNRMHISPNNRNAI... |
| 3 | CTPA_SYNP2/102-182 | SLKVSTSGELSGVGLQINVNPEVDVLEVILPLPGSPAEAAGIEAKDQ... |
| 4 | PRC_HAEIN/244-328 | SFNESINLSLEGIGTTLQSEDDEISIKSLVPGAPAERSKKLHPGDKI... |
| 5 | PRC_ECOLI/238-320 | NTEMSLSLEGIGAVLQMDDDYTVINSMVAGGPAAKSKAISVGDKIVG... |
| 6 | DEGPL_BARHE/289-378 | QQLIEKGLVQRGWLGVQIQPVTKEISDSIGLKEAKGALITDPLKGPA... |
| 7 | HTOA_HAEIN/268-358 | QQILEFGQVRRGLLGIKGGELNADLAKAFNVSAQQGAFVSEVLPKSA... |
| 8 | DEGQ_ECOLI/257-346 | QLIDFGEIKRGLLGIKGTEMSADIAKAFNLDVQRGAFVSEVLPGSGS... |
| 9 | DEGP_ECOLI/279-368 | QMVEYGQVKRGELGIMGTELNSELAKAMKVDAQRGAFVSQVLPNSSA... |
Plotting
Plotting is dead simple.
df["aa_seqs"].seq.plot()
Conversion between NT and AA
Just as with single sequences, you can easily convert between AA and NT forms in dataframes:
# backtranslation returns a Series of nt SeqLikes
df['nt_seqs'] = df["aa_seqs"].seq.back_translate(codon_map=human_codon_map)
df['nt_seqs'].seq.plot()
Creating Multiple Sequence Alignments
Traditionally, multiple sequence alignments are a hassle: you have to export the sequence collection to a FASTA file, run a command line program that exports a text file, and then read back the text file into Python. With SeqLike, you have access to MAFFT to do multiple sequence alignments quickly and easily.
df["aa_seqs"].seq.align().seq.plot()
df["nt_seqs"].seq.align().seq.plot()
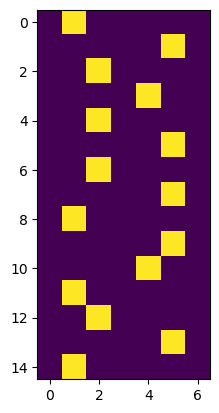
Bulk conversion to array forms
Just as with single SeqLikes, we can convert a collection of SeqLikes in a Pandas series into their array form. The sequences are collated along the first (0th) axis. They need not necessarily be pre-aligned, because padding happens by default. These methods return NumPy arrays, which can be manipulated and viewed as normal. Here we also plot an aligned, index encoded collection of sequences in matplotlib.
# This works for AA SeqLikes...
print(f"{df['aa_seqs'].seq.to_onehot().shape=}") # (num_sequences x length x aa alphabet size)
plt.imshow(df["nt_seqs"].seq.align().seq.to_index())
plt.axis('tight')